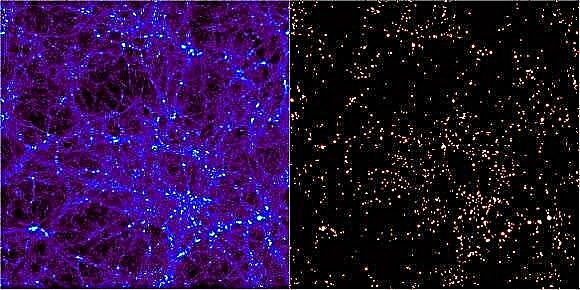
Jedan od uspjeha ΛCDM modela svemira je mogućnost da modeli stvaraju strukture s ljestvicama i distribucijama sličnim onima koje gledamo u časopisu Space. Iako računalne simulacije mogu ponovno stvoriti numeričke svemire u okviru, tumačenje tih matematičkih aproksimacija je izazov samo po sebi. Da bi prepoznali komponente simuliranog prostora, astronomi su morali razviti alate za traženje strukture. Rezultati su bili gotovo 30 neovisnih računalnih programa od 1974. Svaki obećava da će otkriti formirajuću strukturu u svemiru pronalazeći regije u kojima se formiraju orezi tamne materije. Kako bi se ovi algoritmi isprobali, organizirana je konferencija u Madridu u Španjolskoj tijekom svibnja 2010. pod nazivom "Haloes going MAD", na kojoj je 18 ovih kodova testirano kako bi se utvrdilo koliko su dobro složene.
Numeričke simulacije svemira, poput čuvene tisućljetne simulacije, počinju tek „česticama“. Iako su ove kosmološke razmjere nedvojbeno bile male, takve čestice predstavljaju mrlje tamne materije s milijunima ili milijardama solarnih masa. Kako vrijeme prolazi naprijed, oni imaju mogućnost međusobne interakcije slijedeći pravila koja se podudaraju s našim najboljim razumijevanjem fizike i prirodom takve materije. To dovodi do razvijanja svemira iz kojeg astronomi moraju koristiti složene kodove da bi locirali konglomeracije tamne materije unutar kojih bi se formirale galaksije.
Jedna od glavnih metoda takvih programa je traženje malih prekomjernih gustoća, a zatim uzgajanje sferne ljuske oko nje dok gustoća ne opadne na zanemariv faktor. Većina će tada obrezati čestice unutar volumena koji nisu gravitacijski vezani kako bi se osiguralo da se mehanizam za otkrivanje nije samo zahvatio na kratkom, prolaznom grupiranju koje će se vremenom raspasti. Ostale tehnike uključuju pretraživanje u drugim faznim prostorima radi pronalaska čestica sa sličnim brzinama u blizini (znak da su se vezale).
Da bismo usporedili kako se radi svaki od algoritama, provedena su dva ispitivanja. Prva je obuhvaćala niz namjerno stvorenih oreola tamne materije s ugrađenim subhaloima. Budući da je raspodjela čestica namjerno postavljena, ishodi iz programa trebaju ispravno pronaći središte i veličinu halosa. Drugi test bila je punopravna simulacija svemira. Pri tome stvarna distribucija ne bi bila poznata, no sama veličina omogućila bi usporedbu različitih programa na istom skupu podataka da bi se vidjelo koliko slično tumače zajednički izvor.
U oba su ispitivanja svi pronalazili općenito dobro. U prvom ispitivanju bilo je nekih odstupanja na temelju načina na koji su različiti programi definirali mjesto oslonaca. Neki su ga definirali kao vrhunac gustoće, dok su ga drugi definirali kao središte mase. Prilikom pretraživanja podhaloma, činilo se da oni koji koriste pristup faznom prostoru mogu pouzdano detektirati manje formacije, ali nisu uvijek otkrili koje su čestice u klopu zapravo povezane. Za potpunu simulaciju svi su se algoritmi izuzetno dobro složili. Zbog prirode simulacije male vage nisu bile dobro predstavljene, tako da je razumijevanje kako svaka detektiranje tih struktura bilo ograničeno.
Kombinacija ovih testova nije davala prednost jednom algoritmu ili metodi nad bilo kojim drugim. Otkrilo je kako svaki općenito dobro funkcionira jedan prema drugom. Mogućnost za toliko neovisnih kodova, s neovisnim metodama, znači da su nalazi izuzetno snažni. Znanje koje oni prenose o razvoju našeg razumijevanja svemira omogućuje astronomima da izvrše temeljne usporedbe sa promatranim svemirom kako bi testirali takve modele i teorije.
Rezultati ovog testa su sastavljeni u radu koji je predviđen za objavljivanje u nadolazećem broju Monthly Notices of the Royal Astronomical Society.